XML for Salesforce Administrators: DemandTools Configuration
08 May 2019
As we saw with flows, copying and pasting configuration settings within typically point-and-click “business logic tools” is a great reason to be able to read and write XML.
Let’s look at another handy “copy-paste” task for Salesforce admins: ensuring that DemandTools scenarios which should have identical components actually do.
Need extra help on XML? Download Intro to XML, JSON, & YAML – the book
My problem
I suspect I don’t have as many peers as I used to using Validity’s DemandTools since they stopped giving their product to midsize and large nonprofits for free, but if your company can afford it, it’s really an amazing tool for editing data within Salesforce orgs.
One of its nicer features is the ability to save settings describing the data modifications you’d like to do in bulk as files called “scenarios.” Examples:
- In the “MassImpact” module for editing lots of records in a single table at once, you can save settings like, “Look for Contact records owned by Katie and change them to be owned by Anush.” That way, if you ever need to do the same type of “bulk data correction” again, you don’t have to set up the rules all over again.
- In the “Single Table Dedupe” module for finding records that “match” on certain rules and reviewing whether to dedupe them and performing the dedupe, you can save settings like “what my matching rules are,” “what fields I’d like to dummy-check when reviewing the proposed sets,” etc. That way, if you dedupe every day, you don’t have to set up your settings afresh each morning.
As I prepared to hand over the DemandTools “scenarios” I had created for deduping to a colleague who would be taking over my work, I noticed that they were all nearly identical except for the “matching rules.”
Certainly, the list of 50 “fields I’d like to dummy-check” was something I wanted to be identical no matter which of 10 “scenarios” we were using.
That said, my 10 scenarios gotten a little out-of-sync as I’d hand-edited some scenarios over time but left others to languish a bit.
- Q: How to make sure all 10 of my “scenarios” contained the exact same “fields to review” list in the exact same order as each other, without spending all day dragging and dropping in DemandTools? I wanted them to be nice and clean for my colleague.
- A: XML and a text editor to the rescue!
DemandTools “scenarios” are just big XML files saved on your hard drive – which means we Salesforce administrators can edit them as plaintext and change the way DemandTools behaves.
Editing scenarios by hand (no coding)
Step 1: Fix one scenario as usual and note where it “lives”
- Open DemandTools
- Edit one scenario with “clicks” inside of DemandTools, dragging fields around the “fields to show on found duplicates” section of the upper-right quarter of the first page of the “Single Table Dedupe” module of DemandTools, until you’re happy with it. 👍🏼
- Click “Save.”
- Before you click the “Save” button in the pop-up, copy the full file path in the “File name” box to your clipboard and paste it somewhere “safe,” like a new document in Microsoft Notepad or Microsoft Word.
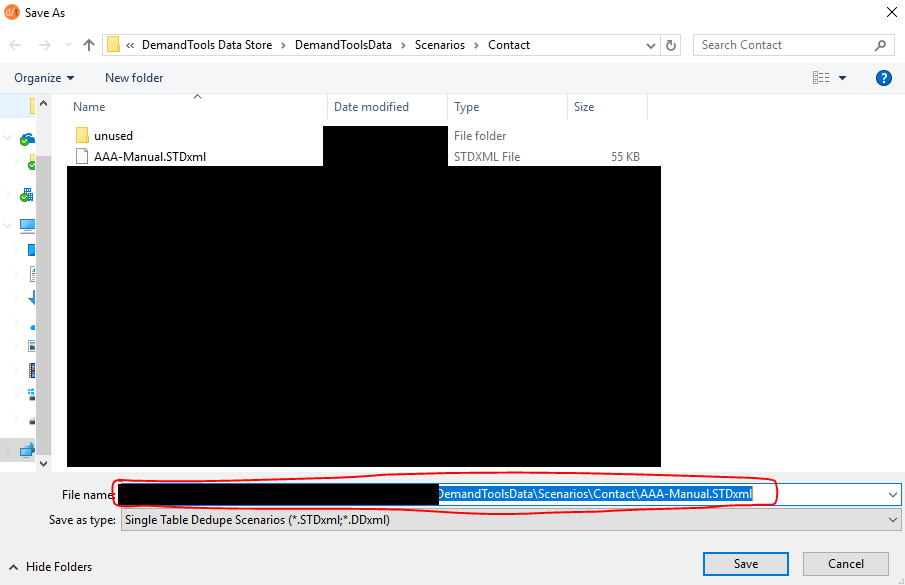

Step 2: Copy text from that scenario
- Open Notepad++, a text editor with powerful capabilities for doing “code folding” with text files that have highly structured contents like XML.
- (“Code folding” means giving you little “+” and “-“ buttons in the left margin so you can expand and hide sections of a document that naturally “clump” together.)
- Click “File” in the top menu, followed by “Open.”
- Paste the file path you copied into the “File name” box and click “Open.”
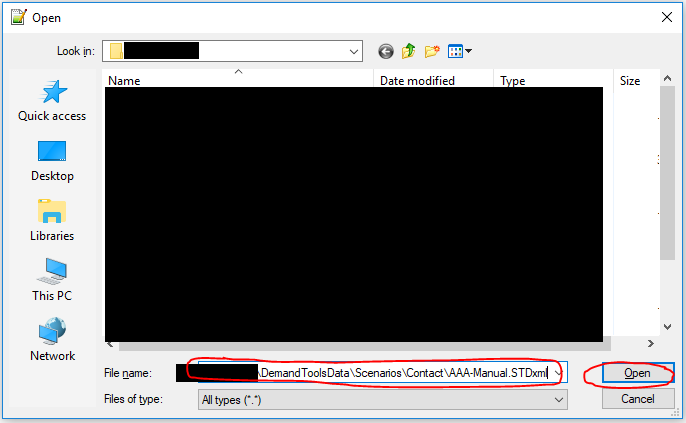
- Click “View” in the top menu.
- Click “Fold All.”
- Click the
+sign next to the tag in line 2 namedSTD_Scenario.

- Near the top of the XML, select the entire
<STD_FieldToShow>...</STD_FieldToShow>tagset (a.k.a. “element”) – all several hundred lines.- I like to do this by putting my cursor at the beginning of the line where this tagset starts (including before any indenting whitespace), then holding “shift” and hitting my down arrow once.

- I like to do this by putting my cursor at the beginning of the line where this tagset starts (including before any indenting whitespace), then holding “shift” and hitting my down arrow once.
- Copy it to your clipboard.
Step 3: Paste “fields to show” into other scenarios
Of course, in this step, you’ll want to be really careful not to paste over the wrong things.
(But hey, that’s why you learned how to read XML, right? So you could be surgically precise with this kind of operation?)
Note: If you’re afraid you might mess up this step, make backups of each of the files you’re about to edit before actually editing them!
- One at a time, open each of the rest of the “
.STDxml” scenario definition files living in the same folder on your hard drive (for me, “Contacts”) as the scenario from which you copiedSTD_FieldToShowin Notepad++. - For each one, do “View” -> “Fold All” and expand the “
STD_Scenario” tag. - For each one, select the entire
<STD_FieldToShow>...</STD_FieldToShow>tagset exactly like you did before, only this time, you’re selecting it because you’re about to paste over it. Make sure it’s all several hundred lines, as before. - Paste the replacement you copied from the first scenario over the text you just selected.
- Save the “
.STDxml” scenario file you just edited and close it.
Step 4: Ta-Da!
- Open DemandTools.
- Open one of the scenarios you just edited with Notepad++.
- Look through the “fields to show on found duplicates” section in the upper-right quarter of the first page.
- It should look exactly how you point-and-click set up the one you edited within DemandTools at the beginning of this process.
Troubleshooting
- Be sure to make copies of the scenarios you’re about to edit and save them somewhere safe before you start.
- If DemandTools throws some sort of error when you try to open a scenario, you may have made a mistake.
- No big deal. Copy/paste your backup file into the folder where your “broken” DemandTools scenario lives and start over.
- If a scenario looks like the way it used to, and not the way you just changed it to look:
- Are you sure you actually saved your changes in Notepad?
- Are you sure you actually edited the correct file representing that scenario?
- Are you sure there was even a difference between the “field list” on the scenario you “copied from” and the scenario you “copied to” in the first place? Are your eyes glazing over? Take a stretch & water break. 🥛
- Feel free to contact me with any questions.
How else can I use this?
All DemandTools scenarios are just XML files, so you can do this in any way that makes sense to you.
Of course, many tasks will be simpler to just do multiple times point-and-click within DemandTools, but if you poke around, you might find other great “copy-paste” candidates.
Not sure where to start in your adventures “poking around?” Try reading my series about learning to read XML and JSON.
Note: If you’re not interested in coding, you can stop reading here.
Thanks for visiting.
I hope this gives you a better idea how much it can speed up the “boring” parts of your job to understand XML.
Editing scenarios with code
Would this really be my blog without a nod to, as they say, “automating the boring stuff?”
We just talked about “looping” over 10 files, looking for lines that mention “STD_FieldToShow,” and either copying everything in between to our clipboard or overwriting everything in between to the contents of our clipboard.
Here’s some Python that does the same thing!
Python is known for its beginner-friendliness, so if you’ve become a copy-paste pro and want to write yourself out of your most boring work, install a setup on your computer and try playing with the code below.
Safety Step: Rather than making a backup of files we’re about to edit, I simply have my program write out new files to a different folder on my computer than the folder in which I found them (C:\example\myoutput).
If I spot-check the output and like what I see, I can always manually copy and paste them into the folder where DemandTools scenario settings files actually belong.
(I use a plugin for Notepad++ called “Compare” to help me verify the difference between my “before” & “after” files.)
Please – Never, ever, ever overwrite your “original” files when editing files on your hard drive with code and you’re not 200% comfortable with what you’re doing.
You can “destroy the important stuff” just as quickly as you can “automate the boring stuff” – the computer doesn’t care which of those you told it to do. 🤖
Algorithm (code recipe)
Here’s what our code does:
- Open the file for the scenario with the “good” fields-to-show list and build a Python list with each line of the file in a separate element of the list. It’s called
copyFileLinesList.- Note that there are double backslashes in the folder.
- The backslash is special when typing text in Python, so you have to put two of them in a row to indicate a single backslash.
- Do some fancy code that grabs the “indices” (line numbers, with the first line of the file being
0) of the first occurrences, each, of our opening and closingSTD_FieldToShowtags. We save these ascopyFromBegIndexandcopyFromEndIndex. - Extract the relevant sublist of “lines of the file” and save it as
copiedSublist. - Loop over all scenario files in the same folder that our “good” file came from, skipping our “good” file. Within this loop, for each file:
- Do similar fancy code to grab the start/end position “indices” of the first
STD_FieldToShowelement and call thempasteOverBegIndex/pasteOverEndIndex. - Extract a sublist of “lines of the file that needs editing” that come before our “block to replace” and save it as
pasteHereFirstSublist. - Extract a sublist of “lines of the file that needs editing” that come after our “block to replace” and save it as
pasteHereLastSublist. - Build a new list called
pasteHereNewListthat’s the concatenation ofpasteHereFirstSublist,copiedSublist, andpasteHereLastSublist.
(See what I did there??!!) - Write
pasteHereNewListto disk as a new file in a different folder (being careful not to overwrite the actual file we’re “editing,” so we have a chance to proofread manually).
- Do similar fancy code to grab the start/end position “indices” of the first
Code
And here’s the code itself:
import os
scenariosfolder = 'c:\\example\\DemandToolsData\\Scenarios\\Contact\\'
outputfolder = 'c:\\example\\myoutput\\'
filetocopy = 'ILoveThisScenario.STDxml'
openTagText = '<STD_FieldToShow'
closeTagText = '</STD_FieldToShow'
with open(scenariosfolder + filetocopy, 'r') as f:
copyFileLinesList = f.readlines()
copyFromBegIndex = next((index for index,lineContents in enumerate(copyFileLinesList) if openTagText in lineContents)) # https://stackoverflow.com/a/40722453 and https://stackoverflow.com/a/9868665
copyFromEndIndex = next((index for index,lineContents in enumerate(copyFileLinesList) if closeTagText in lineContents))
copiedSublist = copyFileLinesList[copyFromBegIndex:copyFromEndIndex+1] # https://stackoverflow.com/a/3451199
for filename in os.listdir(scenariosfolder):
if filename.lower().endswith('.stdxml') and f != filetocopy:
with open(scenariosfolder + filename) as f:
pasteFileLinesList = f.readlines()
pasteOverBegIndex = next((index for index,lineContents in enumerate(pasteFileLinesList) if openTagText in lineContents))
pasteOverEndIndex = next((index for index,lineContents in enumerate(pasteFileLinesList) if closeTagText in lineContents))
pasteHereFirstSublist = pasteFileLinesList[:pasteOverBegIndex]
pasteHereLastSublist = pasteFileLinesList[pasteOverEndIndex+1:]
pasteHereNewList = pasteHereFirstSublist + copiedSublist + pasteHereLastSublist
with open(outputfolder + filename, 'w') as out_f:
out_f.writelines(pasteHereNewList)
#for x in pasteHereNewList: # https://stackoverflow.com/a/899176
#out_f.write("%s\n" % x) # https://stackoverflow.com/a/899176
Troubleshooting
If the output files are “smooshed” into a single line, try “commenting out” the third-to-last line of code with a # at the beginning of the line and “un-commenting” the last two lines of code by removing their leading # symbols and running it again.
As always, contact me with any questions – happy coding, and enjoy your increased productivity (hopefully).
