A Jitterbit Case Study: Higher Education Adventures in Salesforce
04 Nov 2019

Table of Contents
Boy have I been on a database integration adventure these last few weeks. In this series, I’ll review some of the more interesting hoops I jumped through with Jitterbit to load data in CSV files provided by an external admissions application partner (think common app … only this was a much smaller organization) into tables of a Salesforce org.
Intro
Before I launch into a bunch of “how” party tricks, I’d like to spend this post talking about what business purpose I was trying to accomplish.
As I mentioned, I am building a scheduled daily data-load job to fetch 3 CSV files, plus a number of PDF/PNG/etc. files, from a vendor’s server and selectively load their contents into Salesforce.
Source Data Structure
The 3 CSV files are:
students.csv: 1 student per row, containing details like their first name, last name, date of birth, etc.- Each row contains a unique record-identifying value in the
STUDENT_IDcolumn.
- Each row contains a unique record-identifying value in the
applications.csv: 1 admissions application per row, containing details like the level to which they are applying (e.g. “undergraduate”), the type of application they are submitting (e.g. “first-year / transfer”), what they’d like to major in, in which semester they’d like to start, etc.- Each row contains a unique record-identifying value in the
APPLICATION_IDcolumn. - Each row also contains a column with a cross-reference to a
STUDENT_IDvalue.
- Each row contains a unique record-identifying value in the
previous_schools.csv: 1 “previously attended school” per row, containing details like the name of the school they attended, whether it was a high school or a university, the date on which they started attending the school, the date on which they stopped attending the school, their GPA at that school, etc.- There is no unique record-identifying column in this data set.
- Each row contains a column with a cross-reference to a
APPLICATION_IDvalue. - Each row contains a column with a cross-reference to a
STUDENT_IDvalue.
Furthermore, the data I fetch includes a number of PDF, PNG, etc. photographs of transcripts, test scores, and other supplemental documents to support the admissions application. These are named with a strict pattern as follows:
STUDENT_ID, followed by an underscoreAPPLICATION_ID, followed by an underscore- Free text describing what kind of document it is (e.g. “High School transcript 1”)
- A period to separate the filename from the file extension
- A file extension (e.g.
pdf,png, etc.)
To the extent that a collection of files in the same folder can have an “entity-relationship diagram,” here’s how I interpret the data to be “structured:”
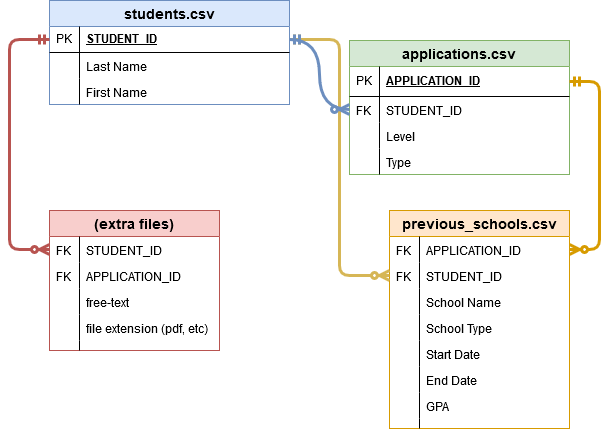
Note: Attentive reader Luke pointed out that the term “student” is often context-specific. For example, working with Salesforce’s Education Data Architecture (“EDA”), he uses the word “student” to mean the junction between a Salesforce Contact and a Salesforce Account (or “school” within an institution).
For the purposes of this blog series, I am using simply the word “student” to describe a person – a human being – because that’s the terminology that was on my mind while writing, seeing as that’s how the vendor named our files. 🙂
Destination Data Structure
Luckily, our senior admin managed to convince the 3rd-party application provider to make sure that their data feed of CSVs broken up into the same object (table) structure and foreign-key/primary-key relationships as our Salesforce org.
(That is, they negotiated to ensure that the CSV files from the vendor would be normalized the way we normalize our Salesforce org.)
In plain English, this means that 1 row of source-CSV-file data should map to 1 row of Salesforce data.
The ERD of our Salesforce org looks almost identical to the one I provided for the “files,” and that’s no accident:
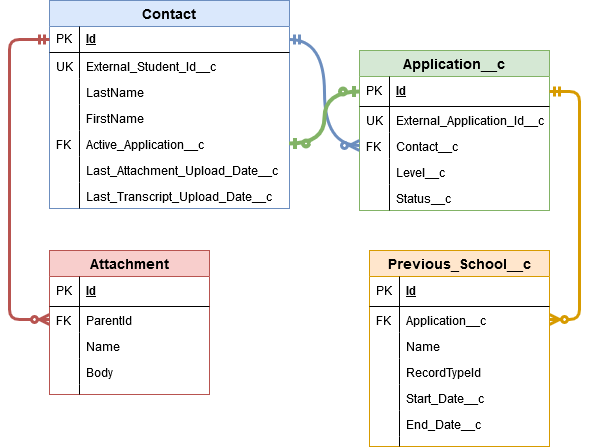
The two main differences are that:
- There’s an actual table connected to
ContactcalledAttachmentthat we will be inserting 1 record per “loose PDF/PNG/etc.” into, loading the file itself into theBodyfield. - There’s a circular lookup to
Application__cfromContactcalledActive_Application__c. Even thoughContactis a parent table toApplication__c… think of this as a “favorite child” sort of field.
There are other lookups, particularly on Application__c, (e.g. “in which term someone would like to start” is a lookup to Term__c), but I’ve tried to keep the basic inter-table relationships simple.
Within Salesforce, Contact and Application__c have unique external ID-typed fields for storing the CSV-side values of STUDENT_ID and APPLICATION_ID, respectively.

What Needs To Go Where
It would be lovely if I could simply map similar tables to each other with a basic UPSERT on external ID, but that isn’t the case.
Let’s take a look at each table in Salesforce and talk about the business rules for loading data into it.
People
Let’s get this out of the way: selling university seats to prospective students is a business-to-customer endeavor, not a business-to-business one.
We don’t bother with Salesforce’s native Lead object. Everyone’s a Contact.
However, to facilitate deduplication, we also have a table called Contact_Temp__c with some Visualforce apps built on top of its data.
Contact_Temp__c is a great place to load potentially-unclean batches of prospective students and sort out who’s who, comparing them against actual Contact records, before updating or inserting records in the Contact table.
Because humans are in charge of actually putting data into Contact, I get off pretty easy when it comes to loading data into Contact_Temp__c.
I’ll show my cards later, but suffice it to say that it’s not complicated and is almost a straightforward “dump each row of the CSV file into a Salesforce record” mapping.
Admissions Applications
Then we have the heart of the matter: data representing an “application for admission” to a program at the university.
I was told that I don’t have to keep Application__c records up-to-date once they’ve been initially loaded (even if any details change on the CSV-file side at a later date), so you’d think the business process would go like this:
- Make sure a
Contactrecord exists with a value inExternal_Student_Id__cthat matchesSTUDENT_IDfromapplications.csv. - Make sure an
Application__crecord does not yet exist with a value inExternal_Application_Id__cmatchingAPPLICATION_IDfromapplications.csv. - If you clear those two preconditions,
INSERTa newApplication__crecord into Salesforce cross-referencing theContactin question and fill in the details as appropriate.
But that’d be easy.
We can’t have that!
It turns out that during the human-driven process of creating Contact records, thanks to the magic of Salesforce automations that people generally find useful to our business processes, placeholder Application__c records get created with almost no details filled in but a Status__c of “Placeholder.”
So it’s actually this:
- Make sure a
Contactrecord exists with a value inExternal_Student_Id__cthat matchesSTUDENT_IDfromapplications.csv. - Make sure an
Application__crecord does not yet exist with a value inExternal_Application_Id__cmatchingAPPLICATION_IDfromapplications.csv. - If you clear those two preconditions, check if the
Contactin question has any existing placeholderApplication__crecords.- If you find 1 or more, pick the oldest one and
UPDATEit, filling in the details as appropriate, including settingStatus__cto “Started.” - If you don’t find any,
INSERTa newApplication__crecord into Salesforce cross-referencing theContactin question and fill in the details as appropriate, including settingStatus__cto “Started.”
- If you find 1 or more, pick the oldest one and
Got it??
Admissions Applications: Bonus Round
We had to set Status__c to “Started” because our Salesforce org has a bazillion automations dependent upon that value.
However, as soon as they’ve had a moment to run, we need to go back through the Application__c records we just UPSERTed and set Status__c to “Submitted.”
Still with me?
Contacts: Bonus Round
Finally, we have to make sure that Active_Application__c on Contact points to the Application__c record we just UPSERTed.
(Exception: If we upserted 2 applications for the same parent Contact, we’ll arbitrarily pick 1 to do the honors.)
Lookup Errors: Bonus Round
Earlier, I mentioned that I hadn’t shown lookup fields within Application__c to objects such as Term__c, Major__c, etc. in the Salesforce entity-relationship diagram above.
However, it is still important to populate these fields correctly.
If applications.csv has data in START_TERM_NAME or MAJOR_NAME that Jitterbit can’t easily match to records within Salesforce’s Term__c or Major__c tables via SOQL query, then I need to e-mail out an error log so our data integrity team can contact the 3rd-party vendor.
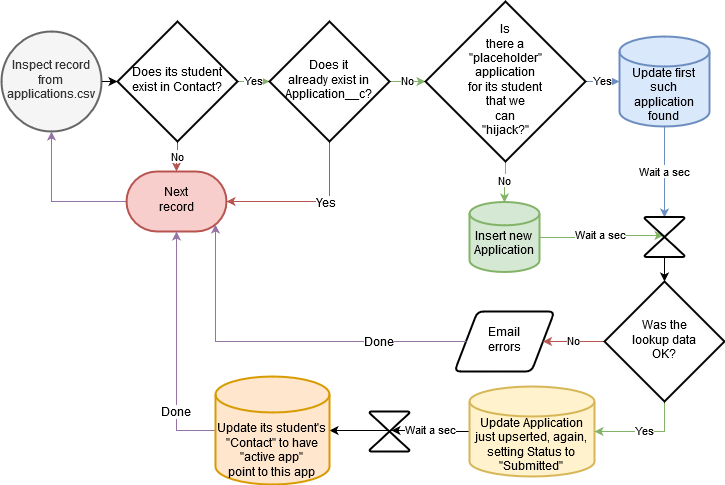
Flowchart
Here’s a flowchart to recap how data needs to flow out of applications.csv:
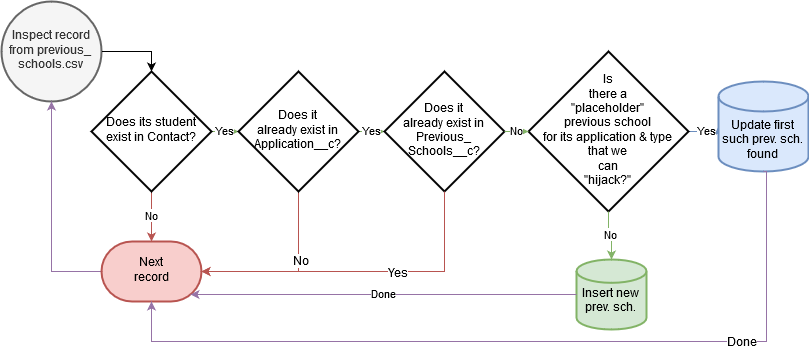
Previous Schools Attended
Loading “previous schools attended” follows similar architecture to loading “admissions applications,” mercifully without “bonus steps:”
- We don’t want to continue to update the Salesforce records corresponding to any CSV records we’ve already data-loaded once.
- We have to do a tricky “take over the first placeholder you find, if applicable” operation because we have Salesforce automations on
Application__cin place that create placeholderPrevious_School__crecords wheneverLevel__cis undergraduate:- 1 high school placeholder
- + 1 college placeholder for transfers
Of course, the first requirement is rendered tricky because previous_schools.csv doesn’t have any sort of obvious “unique record ID” that facilitates matching CSV records against existing Previous_School__c Salesforce records.
Since the business logic for “yes, it’s a match” was simply “do nothing,” I decided there wasn’t severe harm in a slight chance of false positives. I made my matching criteria as broad as seemed reasonable:
- A match on name counts as a match.
- A match on date-range also counts as a match (in case someone “tidied up” the name in Salesforce later on).
- After all, what are the odds of attending two schools over the exact same timespan?
Therefore, our business process for data-loading Previous_School__c records is as follows:
- Make sure a
Contactrecord exists with a value inExternal_Student_Id__cthat matchesSTUDENT_IDfromprevious_schools.csv. - Make sure an
Application__crecord exists with a value inExternal_Application_Id__cthat matchesAPPLICATION_IDfromprevious_schools.csv. - Make sure a
Previous_School__crecord does not yet exist withSCHOOL TYPEmatchingRecordType.DeveloperNameand with either of the following “matches” to data fromprevious_schools.csv:- A
SCHOOL NAMEvalue (CSV) matchingName(Salesforce) - A
START DATEandEND DATEvalue pair (CSV) matchingStart_Date__candEnd_Date__c(Salesforce)
- A
- If you clear those three preconditions, check if the
Application__cin question has any existing placeholderPrevious_School__crecords of the sameSCHOOL TYPE. For blogging purposes, we’ll say that we can recognize a placeholder because itsNameis “~~~PLACEHOLDER~~~.”- If you find 1 or more, pick the oldest one and
UPDATEit, filling in the details as appropriate. - If you don’t find any,
INSERTa newPrevious_School__crecord into Salesforce cross-referencing theApplication__cin question and fill in the details as appropriate.
- If you find 1 or more, pick the oldest one and
Flowchart
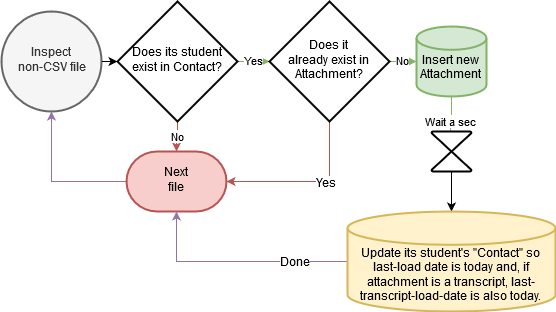
Supplemental Document Attachments
Here’s our business process for loading PDF/PNG/etc. files from the vendor into Attachment in Salesforce:
- Make sure a
Contactrecord exists with a value inExternal_Student_Id__cthat matchesSTUDENT_ID(available by parsing the filename). - Make sure an
Attachmentrecord does not yet exist for thatContactwith a value inNamematching matching the filename. - If you clear those two preconditions,
INSERTa newAttachmentrecord into Salesforce cross-referencing theContactin question (filename toName, contents toBody).
Contacts: Bonus Round
- If we just
INSERTed anyAttachmentrecords for aContact, we have toUPDATEtheContact’sLast_Attachment_Upload_Date__cfield to the current date and time. - If we just
INSERTed anyAttachmentrecords for aContactwhose filenames contain the phrase “transcript,” we have toUPDATEtheContact’sLast_Transcript_Upload_Date__cfield to the current date and time.
Flowchart
Up Next: How I Did It
For the rest of this series, I’ll break these business rules into bite-sized pieces and talk about the architecture I chose in Jitterbit to implement them.
I’m sure we’ll hit a few fun Jitterbit-specific tricks along the way.
For the most part, I suspect I’ll be covering architectural design concepts that should be transferable to any schedule-based ETL tool, so stay tuned, adminelopers, devs, and architects.
