Python pour Salesforce: Énumérer les valeurs uniques à travers plusieurs champs Salesforce
31 Jan 2019
Le SOQL SELECT...COUNT...GROUP BY de Salesforce marche très bien pour énumérer les valeurs uniques d’un seul champs. Mais si on a 50 champs presque identiques, et si on veut trouver les valeurs uniques à travers l’ensemble de tous les champs ? Python à l’aide – lisez pour découvrir comment !
(Vous aimez ? Je fais un webinar en français – venez voir la puissance de Python le 9 fév à 21h CET / 15h EST, et partagez … merci !)
Mon problème
C’est un peu bizarre comme data model, mais dans une organisation Salesforce que je gère, il existe plus que 50 champs personnalisés qui commencent avec le mot “Statut” – un champs pour chaque cours que nous offrons à nos étudiants.
Quand il faut dédupliquer les enregistrements Contact, il y a parfois un conflit entre les valeurs d’un de ces champs pour 2 enregistrements.
J’ai voulu demander à un de nos utilisateurs comment choisir le bon valeur quand il y a un tel conflit.
Pour bien demander un tel guide, j’ai dû savoir quels valeurs existent aujourd’hui parmi tous ces champs.
Et aussi, pour m’assurer que mon expert n’oublie pas une paire de valeurs qui pourraient être en conflit, j’ai voulu dessiner un tableau de correspondances de valeurs comme se voit aux atlas routiers pour indiquer la distance entre une paire de villes.
(Atlas routier … je fais vieille, n’est-ce pas ? Sorte ta smartphone, Katie !)
- Pour le blog, je ne présente que 6 champs personnalisés et 5 valeurs unique trouvés parmi leurs enregistrements.
- En réalité, il y avait plus de 50 champs et 20 valeurs trouvés, parmi 100,000+ Contacts.
C’est 5 million de cellules que j’ai analysé en moins d’une second à la recherche de ces 20 valeurs uniques !
Notez que si j’avais cherché les valeurs uniques d’un seul champs, tel que StatutCours01__c, le SOQL de Salesforce (ou même un rapport Salesforce) aurait suffit :
SELECT StatutCours01__c
FROM Contact
WHERE StatutCours01__c != NULL
GROUP BY StatutCours01__c
ORDER BY StatutCours01__c
C’est le besoin de concaténer les contenus de plus que 50 champs et puis chercher les valeurs uniques qui a crée la nécessité d’exporter l’objet Contact en fichier CSV et d’analyser le fichier avec Python.
Étape 1: Exporter les données de Salesforce
- Allez sur https://workbench.developerforce.com/query.php
- Object: Contact
- Fields: Choissisez tous qui commencent avec “Statut”
- La requête est donc:
SELECT StatutCours01__c,StatutCours02__c, StatutCours03__c,StatutCours04__c, StatutCours05__c,StatutCours06__c FROM Contact - View as: Bulk CSV
- Cliquez sur le bouton “Query”
- Sous “Batches,” lorsque “Status” devient “Completed”, cliquez l’icône de téléchargement (
 ) à la gauche du mot “Id”
) à la gauche du mot “Id” - Enregistrez le fichier au disque dur au chemin
c:\example\tous_c_champs_statut.csv
Notez: Le code Python marcherait aussi bien si j’aurais exporté la table entière de Contacts (avec toutes ses colonnes), et si je l’aurais exportée avec Data Loader.
(Moi j’ai choisi Workbench parce qu’il me présente la liste de champs disponibles en ordre alphabétique.)
Si j’aurais utilisé Data Loader, il aurait fallu modifier la code pour chercher “STATUT” et “__C” en remplissant le variable “nomsDesColsAvecStatut” et non “Statut” + “__c,” comme Data Loader exporte les noms des colonnes en majuscules.
Étape 2 (Python): Énumérer et compter les statuts uniques
Code Python
import pandas
df = pandas.read_csv('c:\\example\\tous_c_champs_statut.csv', dtype=object)
nomsDesColsAvecStatut = [x for x in df.columns if x.startswith('Statut') and x.endswith('__c')]
valeursTrouves = sorted(df[nomsDesColsAvecStatut].stack().unique())
print(valeursTrouves)
print()
print(len(valeursTrouves))
Sortie
['Annulé', 'Enregistré', 'Fini', 'Interessé', 'Pas arrivé']
5
Étape 3 (Python): Créer un fichier CSV façon “atlas routier” pour les correspondances entre statuts possibles
Code Python
import pandas
df = pandas.read_csv('c:\\example\\tous_c_champs_statut.csv', dtype=object)
nomsDesColsAvecStatut = [x for x in df.columns if x.startswith('Statut') and x.endswith('__c')]
valeursTrouves = sorted(df[nomsDesColsAvecStatut].stack().unique())
df2 = pandas.DataFrame(columns=valeursTrouves, index=valeursTrouves)
dejaVu = []
for x in valeursTrouves:
for y in valeursTrouves:
if x == y:
df2[x][y] = '--'
else:
if (x,y) not in dejaVu:
df2[x][y] = 'REMPLISSEZ-MOI'
dejaVu.append((y,x))
else:
df2[x][y] = 'xxx'
df2.to_csv('c:\\example\\graphique_facon_atlas_routier.csv')
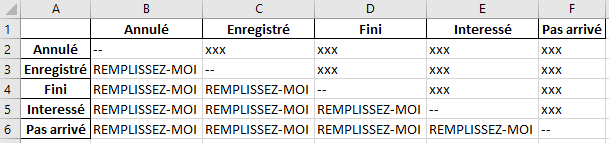
Contenus résultants du fichier graphique_facon_atlas_routier.csv
| Annulé | Enregistré | Fini | Interessé | Pas arrivé | |
|---|---|---|---|---|---|
| Annulé | – | xxx | xxx | xxx | xxx |
| Enregistré | REMPLISSEZ-MOI | – | xxx | xxx | xxx |
| Fini | REMPLISSEZ-MOI | REMPLISSEZ-MOI | – | xxx | xxx |
| Interessé | REMPLISSEZ-MOI | REMPLISSEZ-MOI | REMPLISSEZ-MOI | – | xxx |
| Pas arrivé | REMPLISSEZ-MOI | REMPLISSEZ-MOI | REMPLISSEZ-MOI | REMPLISSEZ-MOI | – |
