Insert, update, and delete from a database to Salesforce
05 Feb 2021
Table of Contents
- Oracle data
- Data mappings
- 1: Oracle “outbound” table: upserts
- 2: Upsert to Salesforce
- 3: Upsert success back to Oracle
- Validate that adding and editing data works
- 4: Oracle “outbound” table: deletes
- 5: Delete from Salesforce
- 6: Delete success back to Oracle
- Misc: Failure emails
- Misc: Lazy deletes
- Misc: Further reading
Oracle User Group meetups attract some great DBAs and database developers. With their permission, I’d like to share a slick little Extract, Transform, Load (“ETL”) data integration pattern that DBA Ken Frank introduced to me, developed with Sidi Mohamed Cheikh Ahmed and Sue Kolles. It does a single-direction sync from Oracle into Salesforce, making sure that inserts, updates, and deletes are all propagated.
The heart of the architecture is to create spare tables inside your database. Compared to the overall cost of Oracle, spare tables here and there as scratch paper are cheap. Keeping a lot of computation inside a full-fledged database engine also reduces the number of API calls to Salesforce – which is good, since they’re quite limited when compared to the “free” computation built into a major database management system.
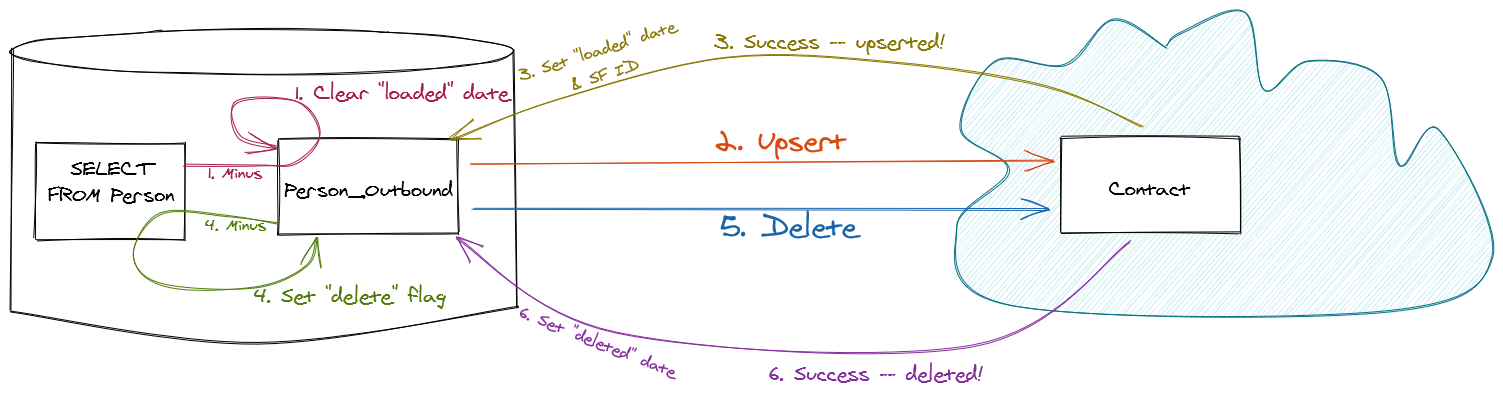
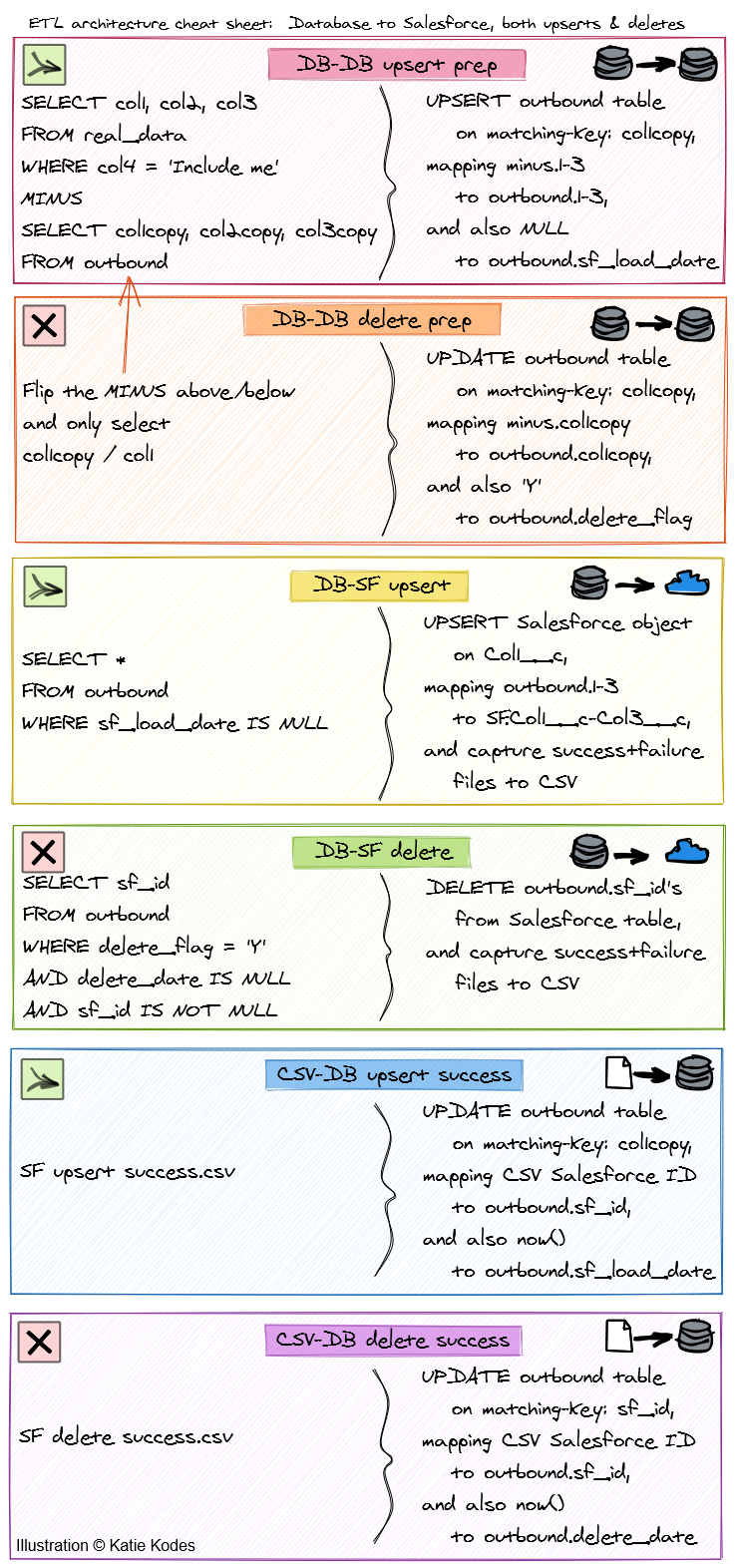
Oracle data
Let’s say you have an Oracle table called person with the following 3 records in it:
| id | lname | fname | company |
|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple |
| B2B2B2 | Borges | Benita | Boiron |
| C3C3C3 | Combs | Cathy | CVS |
Data mappings
The goal, for this article, is to ensure that anything that happens in Oracle’s person table makes its way into in the Contact table of a Salesforce org – even record deletions.
You create a unique case-insensitive external ID field called Oracle_Id__c on Contact over in Salesforce. That’s the field to which person.id should be kept synchronized.
For simplicity’s sake, we’ll ignore the complexities of dealing with Account in Salesforce and just imagine that there’s a Company__c custom field on the Contact table of Salesforce, to which person.company should be kept synchronized.
You also plan to map person.lname to Contact.LastName, as well as person.fname to Contact.FirstName.
DML:
- You’ll be doing
UPSERToperations against Salesforce’sContacttable, overwriting data with fresh updates from Oracle, but never overwriting Oracle data with any details from Salesforce. - You’ll also be doing
DELETEoperations against Salesforce’sContacttable, deletingContactrecords whoseOracle_Id__cvalue no longer appears inperson.idover in Oracle.
1: Oracle “outbound” table: upserts
First, create a table called person_outbound in Oracle. It should have similar columns to person, although it’s fine to rename them, plus 4 new fields.
| oracle_id | lastname | firstname | company | salesforce_contact_id | date_loaded_to_salesforce | delete_flag | date_deleted_from_salesforce |
|---|---|---|---|---|---|---|---|
The first script of your ETL job will sweep data from a SQL query and into DML against person_outbound (insert+update merge keyed on person_outbound.oracle_id).
The SQL query should look something like this – it’s the data you consider important from person, MINUS the data you already have in person_outbound.
SELECT id, lname, fname, company
FROM person
WHERE id IS NOT NULL
MINUS
SELECT oracle_id, lastname, firstname, company
FROM person_outbound
Make the top query as complex as you’d like. For example, perhaps you need to concatenate a fiew fields to serve as equivalent to oracle_id, if you don’t have a naturally suited primary key like I do in person.id.
In the ETL job responsible for DML into person_outbound, map the query’s output fields id, lname, fname, and company to oracle_id, lastname, firstname, and company. Also map a forced-NULL value into date_loaded_to_salesforce.
Then run your ETL job.
Validate that it ran by verifying that SELECT * FROM person_outbound:
| oracle_id | lastname | firstname | company | salesforce_contact_id | date_loaded_to_salesforce | delete_flag | date_deleted_from_salesforce |
|---|---|---|---|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple | ||||
| B2B2B2 | Borges | Benita | Boiron | ||||
| C3C3C3 | Combs | Cathy | CVS |
2: Upsert to Salesforce
Second, build an ETL job that does an UPSERT operation from the following SQL query…
SELECT oracle_id, lastname, firstname, company
FROM person_outbound
WHERE date_loaded_to_salesforce IS NULL
…into to Salesforce’s Contact table, with the upsert keyed on Oracle_Id__c.
Be sure to build the ETL job so that it makes the success/failure responses that come back from Salesforce after upsert available for further ETL operations (you’ll want to save them off to temporary file storage as CSV files).
Map oracle_id to Oracle_Id__c, lastname to LastName, firstname to FirstName, and company to Company__c.
Before running your ETL job, set up your ETL tool to save off the Success file as person_contact_salesforce_upsert_success.csv and the Failure file as person_contact_salesforce_upsert_failure.csv.
If you have a little while (hours) before your ETL tool deletes the CSV files, go ahead and run the ETL job now. If not, wait until you’ve added the next step and then come back to do this.
Log into Salesforce and run the SOQL query:
SELECT Id, Oracle_Id__c, LastName, FirstName, Company__c
FROM Contact
WHERE Oracle_Id__c <> NULL
AND LastModifiedDate > YESTERDAY
Validate that your Salesforce data looks like this:
| Id | Oracle_Id__c | LastName | FirstName | Company__c |
|---|---|---|---|---|
| 003101010101010AAA | A1A1A1 | Amjit | Anush | Apple |
| 003202020202020BBB | B2B2B2 | Borges | Benita | Boiron |
| 003303030303030CCC | C3C3C3 | Combs | Cathy | CVS |
3: Upsert success back to Oracle
The Salesforce success CSV file person_contact_salesforce_upsert_success.csv should have 1 row for every row of data you sent to the UPSERT operation, with a Salesforce Id appended at left.
Third, build an ETL job that does an update operation against person_outbound, matching against person_outbound.oracle_id.
Map the CSV file’s ORACLE_ID column to oracle_id, the CSV file’s Salesforce ID column (some ETL tools might call it ID; others might call it SF_ID, etc.) to salesforce_contact_id, and the current date & time to date_loaded_to_salesforce.
Run the ETL job if you haven’t already. If you were working in an ETL tool that would have cleaned up the existence of person_contact_salesforce_upsert_success.csv immediately after the Salesforce upsert operation, chain these two operations together, with the “back to Oracle” operation following on the heels of the “upsert into Salesforce” operation, and then run the “upsert into Salesforce” operation.
Validate that it ran by verifying that SELECT * FROM person_outbound:
| oracle_id | lastname | firstname | company | salesforce_contact_id | date_loaded_to_salesforce | delete_flag | date_deleted_from_salesforce |
|---|---|---|---|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple | 003101010101010AAA | 2/4/2021 6:49:48 PM | ||
| B2B2B2 | Borges | Benita | Boiron | 003202020202020BBB | 2/4/2021 6:49:48 PM | ||
| C3C3C3 | Combs | Cathy | CVS | 003303030303030CCC | 2/4/2021 6:49:48 PM |
Validate that adding and editing data works
Edit the contents of person so that Cathy gets a new job at Coolors and a new person exists named Darweesh:
| id | lname | fname | company |
|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple |
| B2B2B2 | Borges | Benita | Boiron |
| C3C3C3 | Combs | Cathy | Coolors |
| D4D4D4 | Daher | Darweesh | Dell |
If you were to re-run the query (with the MINUS) behind the database-to-database ETL job we built up top, you’d see these results:
| id | lname | fname | company |
|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple |
| B2B2B2 | Borges | Benita | Boiron |
| C3C3C3 | Combs | Cathy | Coolors |
| D4D4D4 | Daher | Darweesh | Dell |
After re-running that first ETL job, SELECT * FROM person_outbound should return:
| oracle_id | lastname | firstname | company | salesforce_contact_id | date_loaded_to_salesforce | delete_flag | date_deleted_from_salesforce |
|---|---|---|---|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple | 003101010101010AAA | 2/4/2021 6:49:48 PM | ||
| B2B2B2 | Borges | Benita | Boiron | 003202020202020BBB | 2/4/2021 6:49:48 PM | ||
| C3C3C3 | Combs | Cathy | Coolors | 003303030303030CCC | |||
| D4D4D4 | Daher | Darweesh | Dell |
Note that Cathy’s date_loaded_to_salesforce has been cleared out and Darweesh doesn’t yet have one.
When you re-run the Database-to-Salesforce 2nd ETL job, it should make Salesforce look like this:
Validate that your Salesforce data looks like this:
| Id | Oracle_Id__c | LastName | FirstName | Company__c |
|---|---|---|---|---|
| 003101010101010AAA | A1A1A1 | Amjit | Anush | Apple |
| 003202020202020BBB | B2B2B2 | Borges | Benita | Boiron |
| 003303030303030CCC | C3C3C3 | Combs | Cathy | Coolors |
| 003404040404040DDD | D4D4D4 | Daher | Darweesh | Dell |
Finally, run the CSV-to-database 3rd ETL job, which should make SELECT * FROM person_outbound should look like this:
| oracle_id | lastname | firstname | company | salesforce_contact_id | date_loaded_to_salesforce | delete_flag | date_deleted_from_salesforce |
|---|---|---|---|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple | 003101010101010AAA | 2/4/2021 6:49:48 PM | ||
| B2B2B2 | Borges | Benita | Boiron | 003202020202020BBB | 2/4/2021 6:49:48 PM | ||
| C3C3C3 | Combs | Cathy | Coolors | 003303030303030CCC | 2/4/2021 7:15:15 PM | ||
| D4D4D4 | Daher | Darweesh | Dell | 003404040404040DDD | 2/4/2021 7:15:15 PM |
Congratulations – you have new records and record updates flowing from Oracle to Salesforce. Put it on a schedule and enjoy!
4: Oracle “outbound” table: deletes
The fourth job of your ETL project will, just like the first one, sweep data from a SQL query and into DML against person_outbound (insert+update merge keyed on person_outbound.oracle_id).
However, you’re going to shorten the SELECT field list and flip the queries on the two sides of the MINUS.
Now it’s the data you already have in person_outbound, MINUS the data you consider important from person.
SELECT oracle_id
FROM person_outbound
MINUS
SELECT id
FROM person
WHERE id IS NOT NULL
In the ETL job responsible for DML into person_outbound, map the query’s output field oracle_id to oracle_id. Also map a forced value of 'Y' into delete_flag.
Delete Benita from person, then run your ETL job.
Validate that it ran by verifying that SELECT * FROM person_outbound:
| oracle_id | lastname | firstname | company | salesforce_contact_id | date_loaded_to_salesforce | delete_flag | date_deleted_from_salesforce |
|---|---|---|---|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple | 003101010101010AAA | 2/4/2021 6:49:48 PM | ||
| B2B2B2 | Borges | Benita | Boiron | 003202020202020BBB | 2/4/2021 6:49:48 PM | Y | |
| C3C3C3 | Combs | Cathy | Coolors | 003303030303030CCC | 2/4/2021 7:15:15 PM | ||
| D4D4D4 | Daher | Darweesh | Dell | 003404040404040DDD | 2/4/2021 7:15:15 PM |
5: Delete from Salesforce
Fifth, build an ETL job that does a DELETE operation from the following SQL query…
SELECT salesforce_contact_id
FROM person_outbound
WHERE delete_flag = 'Y'
AND date_deleted_from IS NULL
AND salesforce_contact_id IS NOT NULL
…into to Salesforce’s Contact table, with the delete keyed on mapping the query’s salesforce_contact_id field to the Salesforce Contact table’s Id field.
Be sure to build the ETL job so that it makes the success/failure responses that come back from Salesforce after upsert available for further ETL operations (you’ll want to save them off to temporary file storage as CSV files).
Map salesforce_contact_id to Id.
Before running your ETL job, set up your ETL tool to save off the Success file as person_contact_salesforce_delete_success.csv and the Failure file as person_contact_salesforce_delete_failure.csv.
If you have a little while (hours) before your ETL tool deletes the CSV files, go ahead and run the ETL job now. If not, wait until you’ve added the next step and then come back to do this.
Log into Salesforce and run the SOQL query:
SELECT Id, Oracle_Id__c, LastName, FirstName, Company__c
FROM Contact
WHERE Oracle_Id__c <> NULL
AND LastModifiedDate > YESTERDAY
Validate that your Salesforce data looks like this:
| Id | Oracle_Id__c | LastName | FirstName | Company__c |
|---|---|---|---|---|
| 003101010101010AAA | A1A1A1 | Amjit | Anush | Apple |
| 003303030303030CCC | C3C3C3 | Combs | Cathy | Coolors |
| 003404040404040DDD | D4D4D4 | Daher | Darweesh | Dell |
Now that Benita has been removed from Salesforce, we just need to tell person_outbound that the deed is done.
6: Delete success back to Oracle
The Salesforce success CSV file person_contact_salesforce_delete_success.csv should be a simple 1-column CSV file full of Salesforce IDs that no longer exist.
Sixth, build an ETL job that does an update operation against person_outbound, matching against person_outbound.salesforce_contact_id.
Map the CSV file’s Salesforce ID column (some ETL tools might call it ID; others might call it SF_ID, etc.) to salesforce_contact_id, and the current date & time to date_deleted_from_salesforce.
Run the ETL job if you haven’t already. If you were working in an ETL tool that would have cleaned up the existence of person_contact_salesforce_delete_success.csv immediately after the Salesforce delete operation, chain these two operations together, with the “back to Oracle” operation following on the heels of the “delete from Salesforce” operation, and then run the “delete from Salesforce” operation.
Validate that it ran by verifying that SELECT * FROM person_outbound looks like this:
| oracle_id | lastname | firstname | company | salesforce_contact_id | date_loaded_to_salesforce | delete_flag | date_deleted_from_salesforce |
|---|---|---|---|---|---|---|---|
| A1A1A1 | Amjit | Anush | Apple | 003101010101010AAA | 2/4/2021 6:49:48 PM | ||
| B2B2B2 | Borges | Benita | Boiron | 003202020202020BBB | 2/4/2021 6:49:48 PM | Y | 2/4/2021 7:30:30 PM |
| C3C3C3 | Combs | Cathy | Coolors | 003303030303030CCC | 2/4/2021 7:15:15 PM | ||
| D4D4D4 | Daher | Darweesh | Dell | 003404040404040DDD | 2/4/2021 7:15:15 PM |
Since Benita now has a non-null date_deleted_from_salesforce value, she won’t be caught up again in tomorrow’s delete-sweep from Oracle to Salesforce.
Misc: Failure emails
If your e-mail tool allows you to attach failed records files to e-mails by by wildcard, you may be able to send a single e-mail for all the day’s failed Salesforce DML operations by attaching *_failure.csv.
Misc: Lazy deletes
One issue they noticed is that when person is a fragile materialized view that sometimes gets truncated without being properly re-populated on a given morning, the deletion logic can unnecessarily delete millions of records from Salesforce.
For such source tables, they put a job at the beginning of all this that writes the maximum number of rows ever seen in person and a datestamp to a 2-column, 1-row table called person_highest_row_count. (That is, if today’s rowcount is greater than the existing record, it overwrites the record with a new all-time high. Otherwise, it leaves it alone.)
They have another job squeezed in between the update jobs and the delete jobs. It checks the current size of person. If it’s less than 95% of the size of the all-time-high row count, delete operations are skipped and an error e-mail is sent out to appropriate staff.
Thanks, Sue, Sidi, & Ken, for demonstrating a simple yet powerful ETL architecture!
Misc: Further reading
- In Jitterbit, you can combine parts 2 and 3 – or parts 5 and 6 – into a single operation without an intermediate CSV file. See “Jitterbit: backfill Salesforce ID into a database.”
